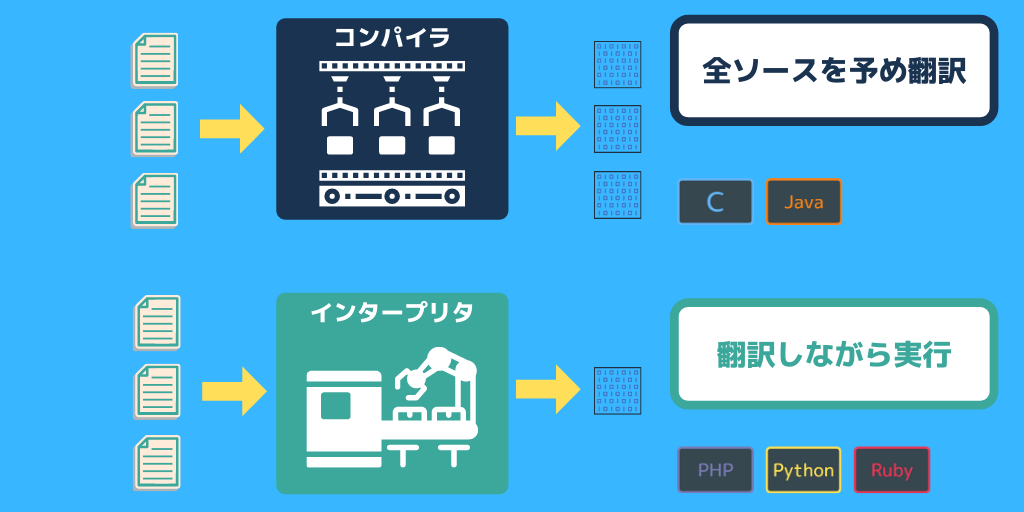
文章の「類似度」をスコアリング!リライトチェッカーを作る
この記事の動画版はこちら(画像クリックでYoutubeに飛びます)

今回作るツールは・・・
今回は、文章同士の類似度を判定してスコアリングする「リライトチェッカーツール」を作っていきたいと思います。
仕事をしていると、件数の多いデータ処理とか、単純作業を繰り返し行わなければならない事ってありますよね。
僕はそういった作業があまり得意ではないので、大抵プログラムを書いて自動化してします。
ちょうど今も、自分のTwitterの過去の投稿を分析する必要があり、Twitterを見ながら解析用のレポートにまとめているんですが、大切なことは何度も繰り返し言ったりしているので「微妙に言い回しの異なる、似たような投稿」がいくつかあるんですね。
これらは「重複データ」として1つにまとめたいんですが、ツイート1件に対して、それと「同じようなことを言っているツイート」があるかどうかを1件1件、目で見ていくのはとても大変です。
なので、今回はこれをプログラムにやらせてみようと思います。
まずはデータベース作成
それでは、早速作っていきましょう!
まずはTwitterから自分のツイートデータを取得して、解析用の一時データベースに保存します。
先にデータベースを作っておきましょう。
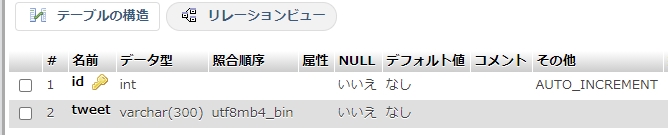
TwitterのIDと、ツイート文面が保存出来れば良いのでこれで充分ですね。
【POINT】
Twitterは絵文字を使うこともあるので、照合順序は「utf8mb4」にしておきます。
Twitter APIを使うための下準備
続いて、Twitter APIを使うための下準備をします。
<?php require_once(dirname(__FILE__).'/twitteroauth-master/autoloader.php'); use Abraham\TwitterOAuth\TwitterOAuth; // TwitterOAuthオブジェクト作成 $connection = new TwitterOAuth(TWITTER_CONSUMER_KEY, TWITTER_CONSUMER_SECRET, TWITTER_ACCESS_TOKEN, TWITTER_ACCESS_TOKEN_SECRET);
必要なライブラリを読み込み、TwitterOAuthオブジェクトを作成します。
Twitterからツイートを取得
次は、実際にTwitterからツイートを取得するコードを書いていきます。
※各種パラメーターの詳細は、APIリファレンスに記載されています。
// APIに送るパラメーター $params = [ 'count' => '200', 'screen_name' => 'senseshare_inc', 'trim_user' => 'true', 'exclude_replies' => 'true', 'include_rts' => 'false', ]; $tweets = $connection->get('statuses/user_timeline', $params); if (empty($tweets)) { echo 'rate limit'; break; } foreach ($tweets as $tweet) { echo "{$tweet->text}<br>"; }
Twitter APIの取得制限が200件なので、再帰的に取得
今回は、直近500件のツイートを対象にしたいんですが、Twitter APIでは1回につき最大200件までしか受け取れないため、再帰的に全件取得するように取得部分のコードを改造します。
$count = 0; do { $tweets = $connection->get('statuses/user_timeline', $params); if (empty($tweets)) { echo 'rate limit'; break; } foreach ($tweets as $tweet) { echo "[{$count}] {$tweet->text}<br>"; $count++; // 500件で終了 if ($count > 500) { break 2; } } $params['max_id'] = count($tweets) > 1 ? $tweets[count($tweets) - 1]->id_str : null; } while ($params['max_id'] != null);
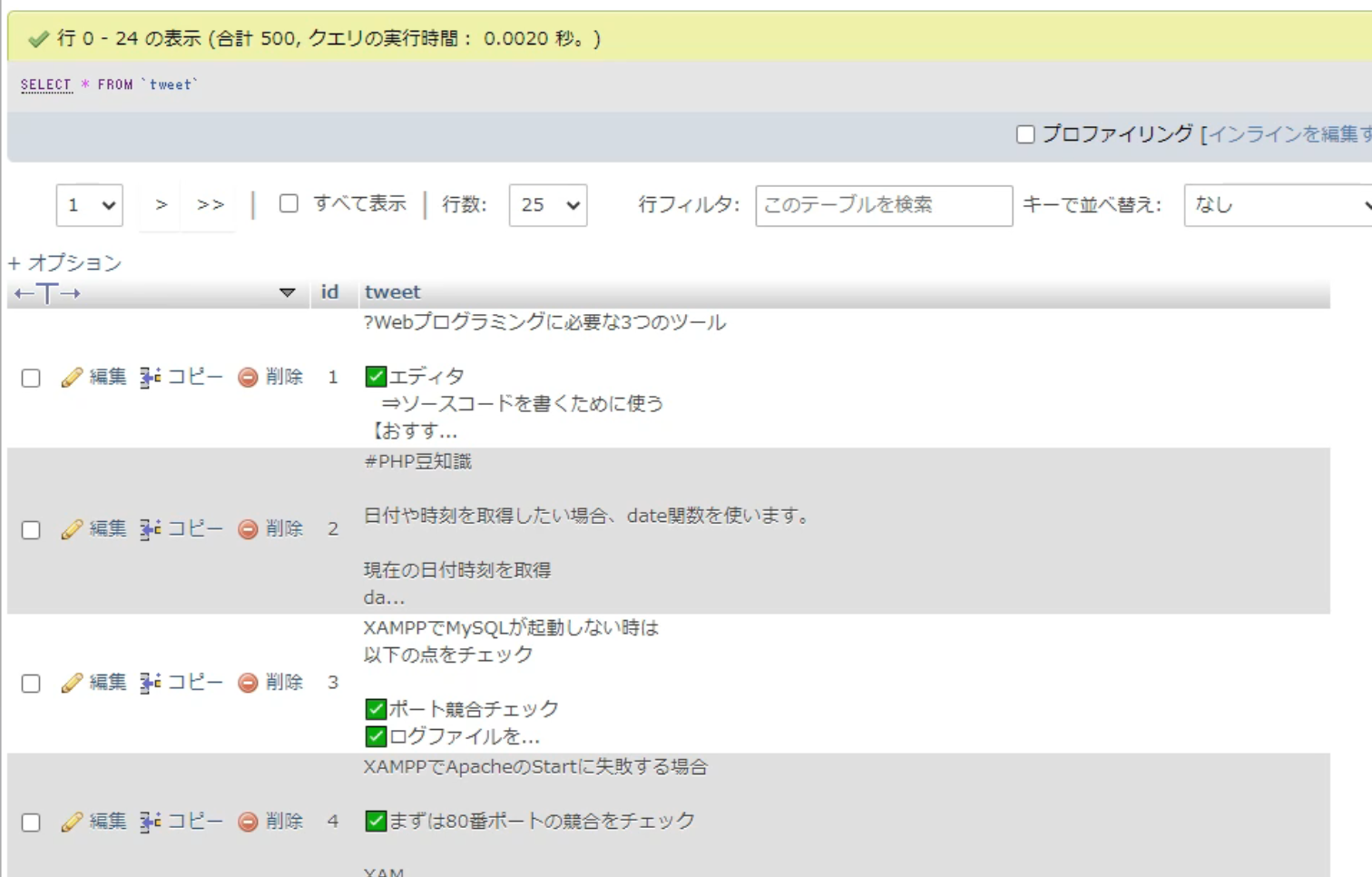
ここで、一度実行してみましょう。

自分のツイートが「500件」取得出来ました。
取得したデータをデータベースに保存
これを先ほどの一時データベースに保存します。
// 取得したツイートをDBに登録 $stmt = $pdo->prepare("INSERT INTO tweet (tweet_id, tweet) VALUES (:tweet_id, :tweet)"); $stmt->bindValue(':tweet_id', $tweet->id_str, PDO::PARAM_STR); $stmt->bindValue(':tweet', $tweet->text, PDO::PARAM_STR); $stmt->execute();
自動チェックプログラムの作成
次は、自動チェックプログラムを書いていきます。
先ほど取得した500件のデータに対して1件ずつ確認していくので、
1件につき自分以外の499件のチェック、つまり
500 x 499件 = 249,500件
の確認作業ですね。
もし1件1件目で見て確認していったとしたら、文章同士が似ているかどうかを「1件」につき「1秒」で判断していったとしても・・・
249500件 / 60秒 / 60分 = 69.30555555555556時間
約70時間かかるようです。(これはちょっと人力ではやりたくないですね・・・)
では作っていきましょう!
データベースから全データを取得
まずは、データベースから先ほど登録した全データを取り出し、
$stmt = $pdo->query("SELECT * FROM tweet"); $tweet_list = $stmt->fetchAll();
ループを入れ子にしてチェックしていきます。
チェックはPHPの「similar_text」関数を使って、類似スコアが60点以上のものを抽出するようにしてみましょう。
echo '<table border="1">'; echo '<tr><td>オリジナル</td></tr>'; foreach ($tweet_list as $tweet) { echo '<tr>'; echo '<td>'.htmlspecialchars($tweet['tweet']).'</td>'; foreach ($tweet_list as $comp_data) { if ($tweet['id'] != $comp_data['id']) { similar_text($tweet['tweet'], $comp_data['tweet'], $result); $result = sprintf('%02.1f', $result); if ($result > 60) { echo '<td>'.'<span style="color:red">【'.$result.'】</span>'.htmlspecialchars($comp_data['tweet']).'</td>'; } } } echo '</tr>'; } echo '</table>';
処理時間も計測しておきましょう。
開始時間と、
$start_time = date('H:i:s');
終了時間を記録し
$end_time = date('H:i:s');
処理完了後に表示させます。
echo '【START】'.$start_time.'<br>'; echo '【END】'.$end_time.'<br>'; echo '【処理時間(秒)】'.(strtotime($end_time) - strtotime($start_time));
これで、OKです。
実行!
実行結果はこんな感じになりました。
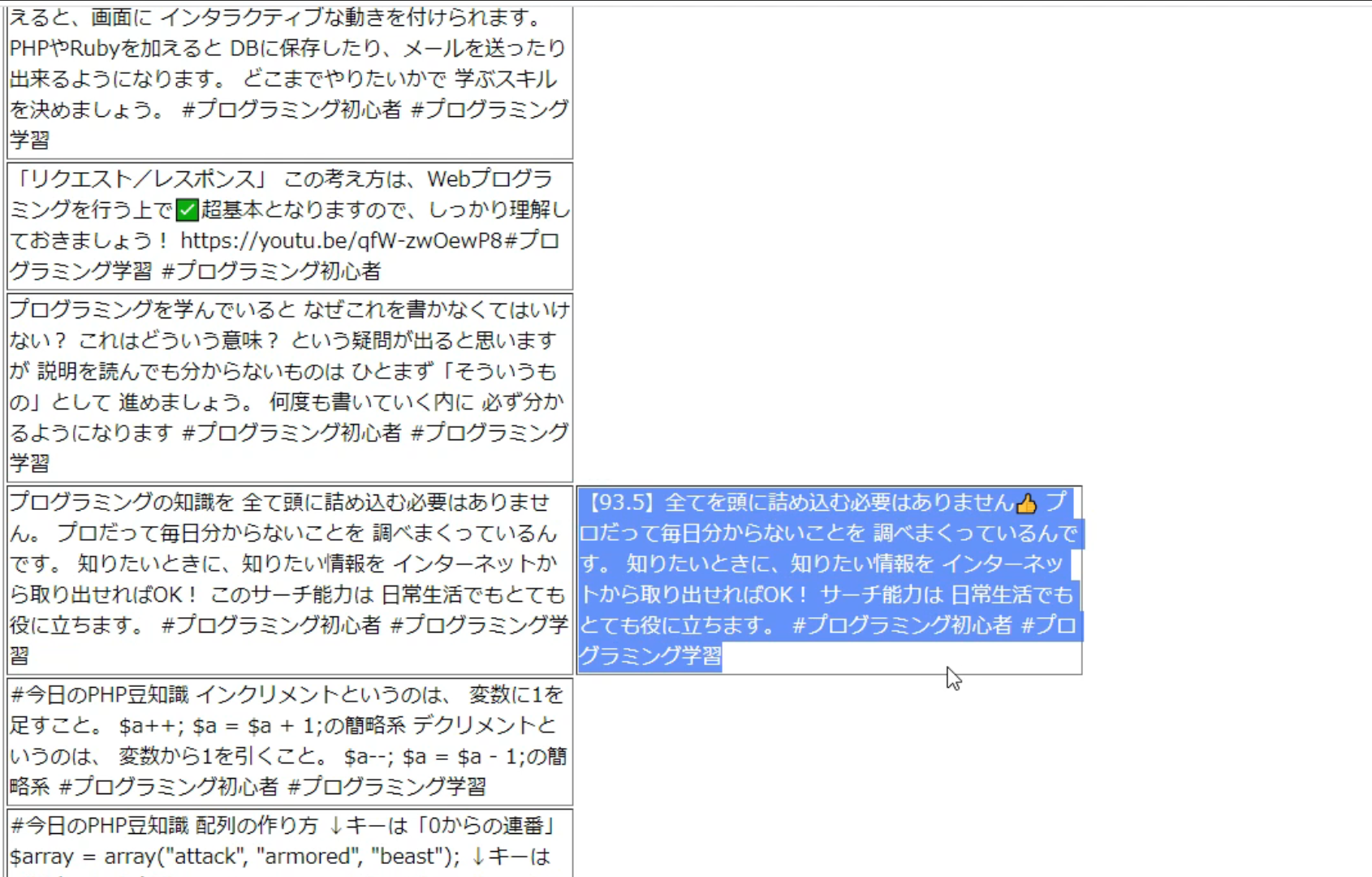
言い回しの似ているツイートがいくつかありました。
微妙な言い回しの違いですが、ちゃんと拾ってきています。
類似スコアが高いほど、似ているということですね。
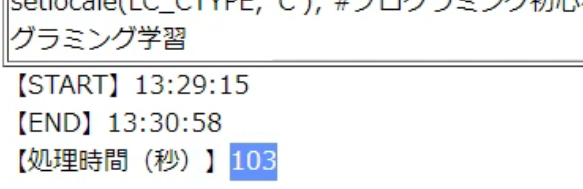
処理時間は「103秒」でした。1分半くらいですね。
正しく判定出来ているようなので、あとは類似スコア60点以上のデータをDBから削除するように変更すれば、本来の目的である「重複ツイートを除外したツイートの一覧」が作成出来ます。
このデータをDBからCSVでエクスポートして、これをExcelなどで読み込めば仕事完了です!
作業結果まとめ
ということで今回は、文章同士の類似度を判定してスコアリングする「リライトチェッカーツール」をざっくりと作ってみました。
1件1件目で見ていたら約70時間かかるところ、プログラムだと1分半で完了です。
もし目で見てやっていたら、たぶん終盤は疲れてチェックが適当になってしまっていたと思いますが、プログラムなら最後まで漏れもなく安心です。
また、今後同じような分析を行う場合にも、このプログラムが再利用できますね。
ちなみに、今回はTwitterの投稿を解析しましたが、他にも例えば
・ブログやニュースの原稿のチェック
・企業のカスタマーサポートの過去のお問い合わせ履歴のデータ分析
・テストの採点の補助
など、色々な作業の自動化にも応用できると思います。
こんな感じで、プログラミングスキルはアプリやサービスを作るだけでなく、自分のために働くロボットを自ら作り出していくことも可能なんです。
プログラミングスキルを活用して、自由な時間をたくさん作っていきましょう!

Webプログラマー暦20年。自分で使うツールは、基本的に1人でゼロから自作。オールマイティなプログラミングの知識とスキルを学べる「フルスタックエンジニア マスター講座」を開講中。生徒さん1人1人に合わせてしっかりサポートしていきます!
ぜひフォローしておいてください。